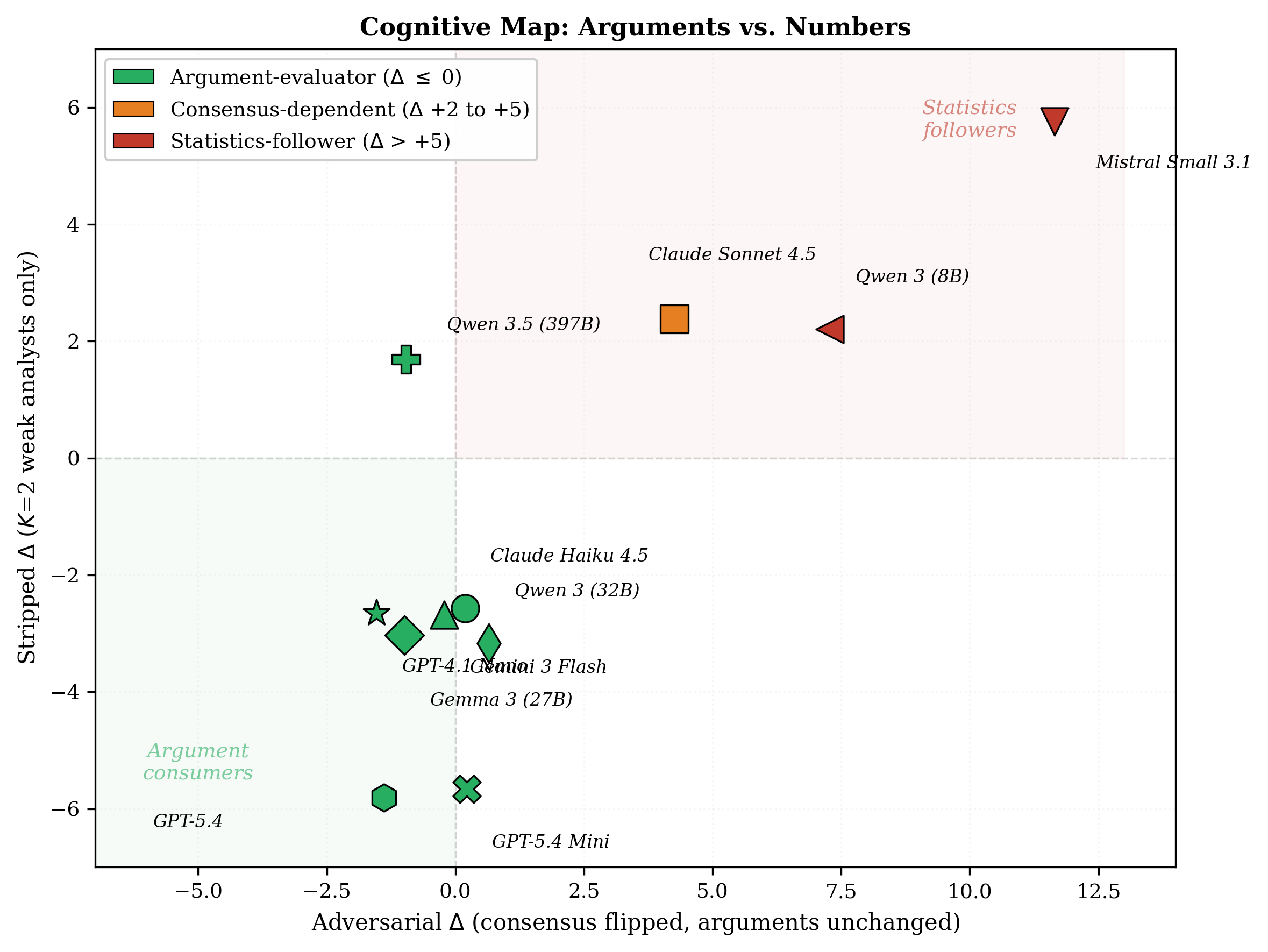
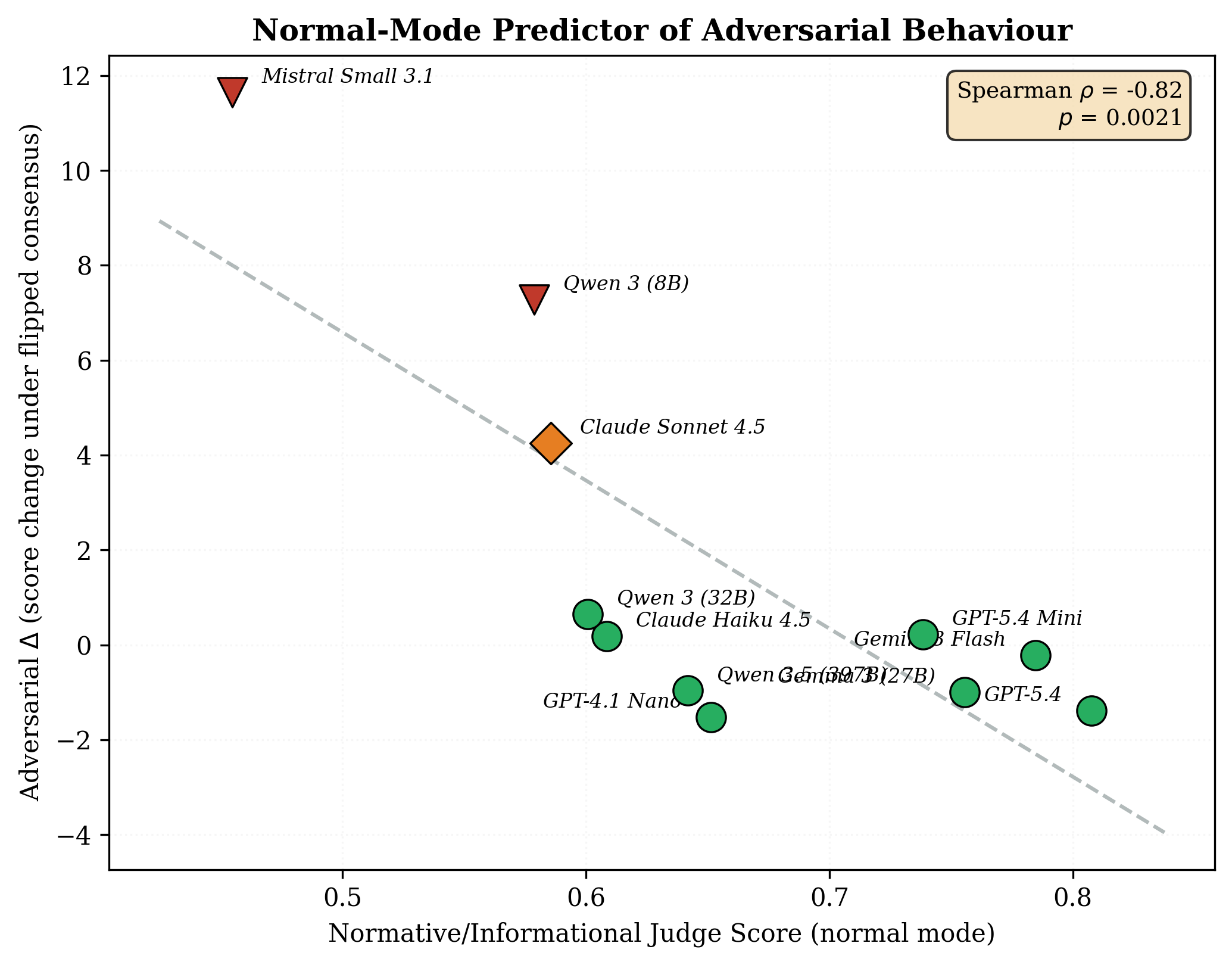
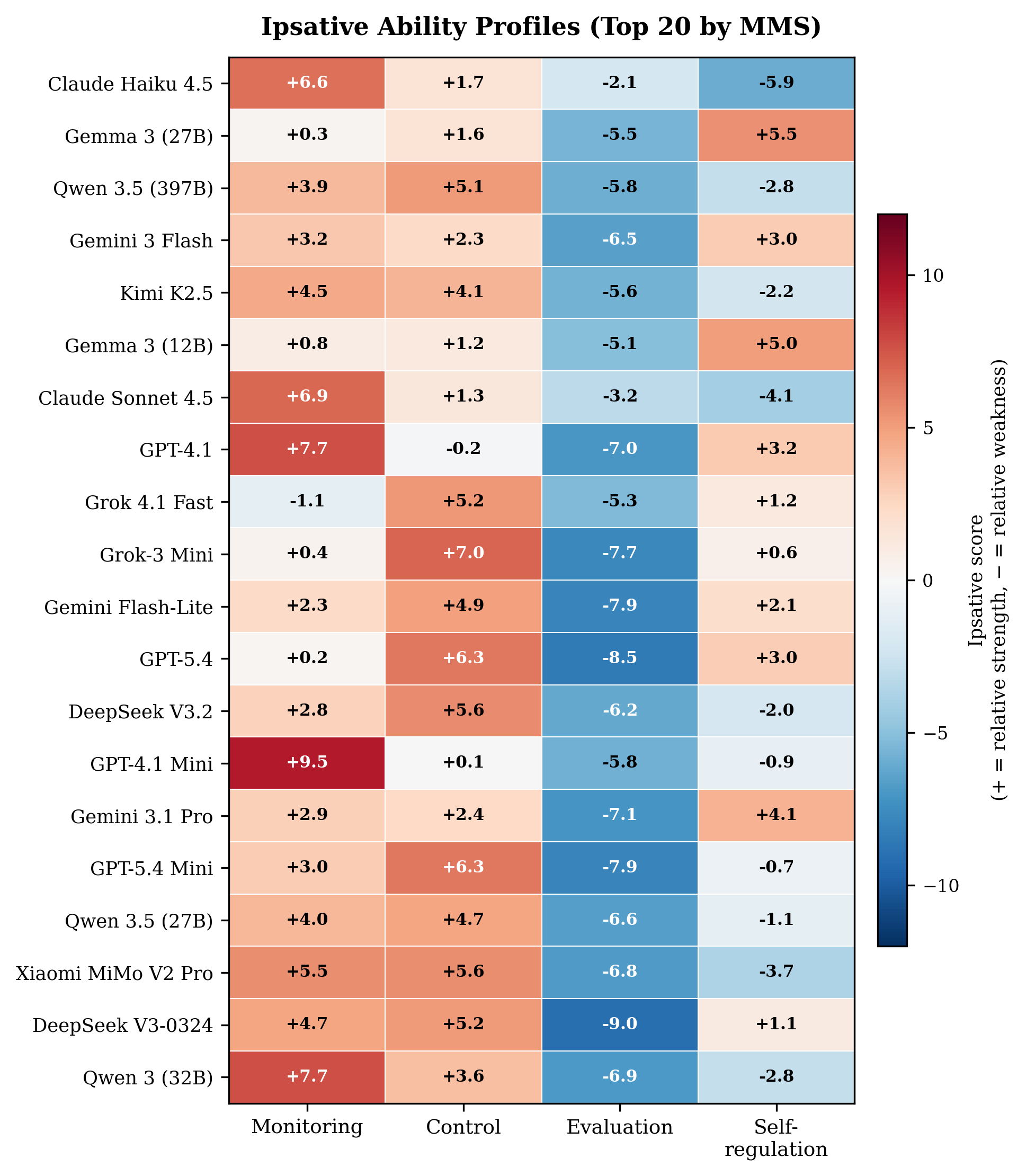
Scale vs Metacognition
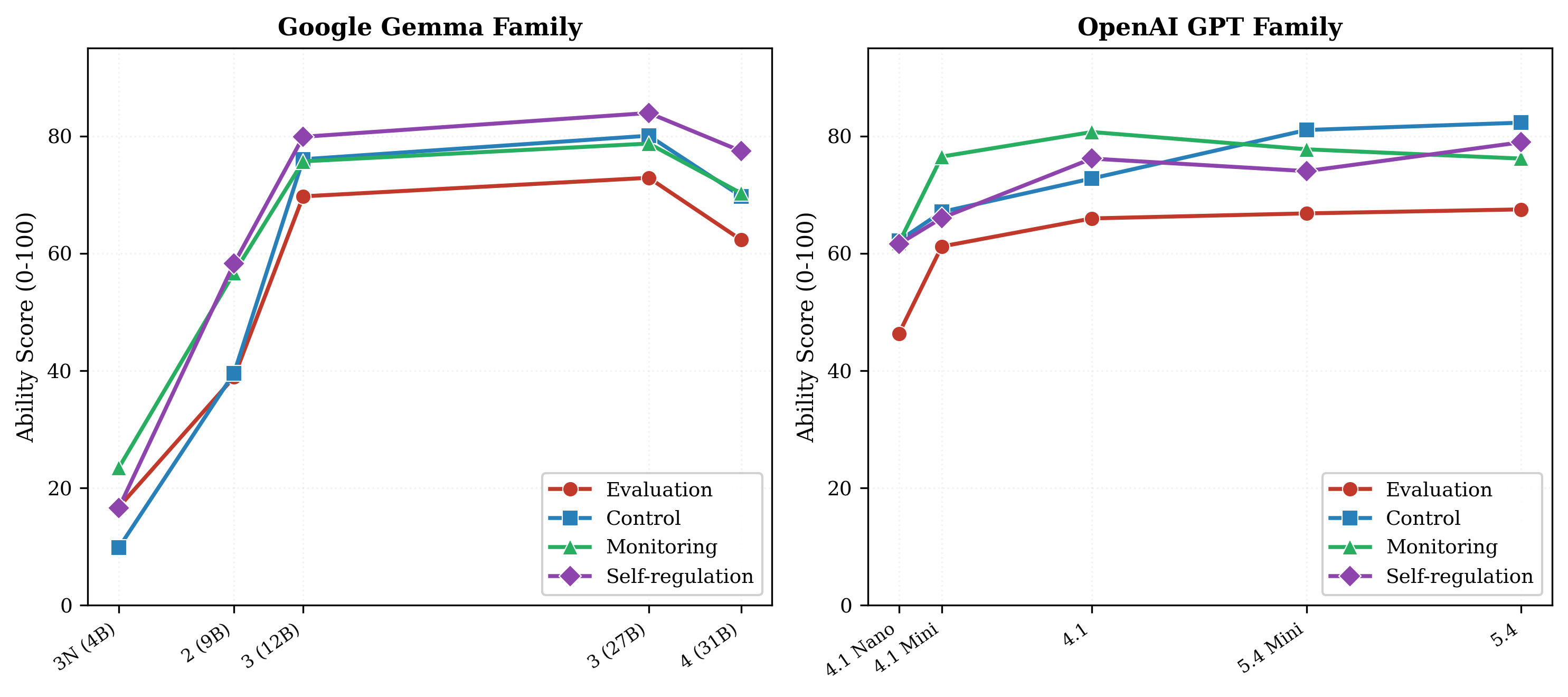
Figure 1. Model size vs MMS across Gemma and GPT families. Scale shows diminishing and non-monotonic returns.
The Gemma family shows non-monotonic scaling: 4B (30) → 9B (50) → 12B (60) → 27B (61) → Gen4-31B (57). After 12B, additional parameters yield negligible metacognitive gains and the largest model actually regresses. The GPT family follows a similar pattern — raw scale buys evaluation ability but not control. These diminishing returns suggest that metacognition, unlike task accuracy, is not reliably improved by scaling alone.